

With the blog finally put in place and the tagging system (and even the deletion functioning properly), finally this site can get a bit more life put into it. To start, I will be covering the process it took in order to fully implement the blog page from start to finish. Because the CMS manages to touch pretty much all facets of the site (front-end, back-end API, CDN management), it turned out to be significantly more time consuming than pretty much everything up until this point. This update will be split up into three parts because a significant amount of change has happened since the first-post:
Front-End
Back-End
Infra (Dev-Ops)
With that being stated, this post represents the Front-End update post from the given three. As the other posts go up, this post will be modified to reflect the paths to the new posts.
Designing a CMS From Scratch
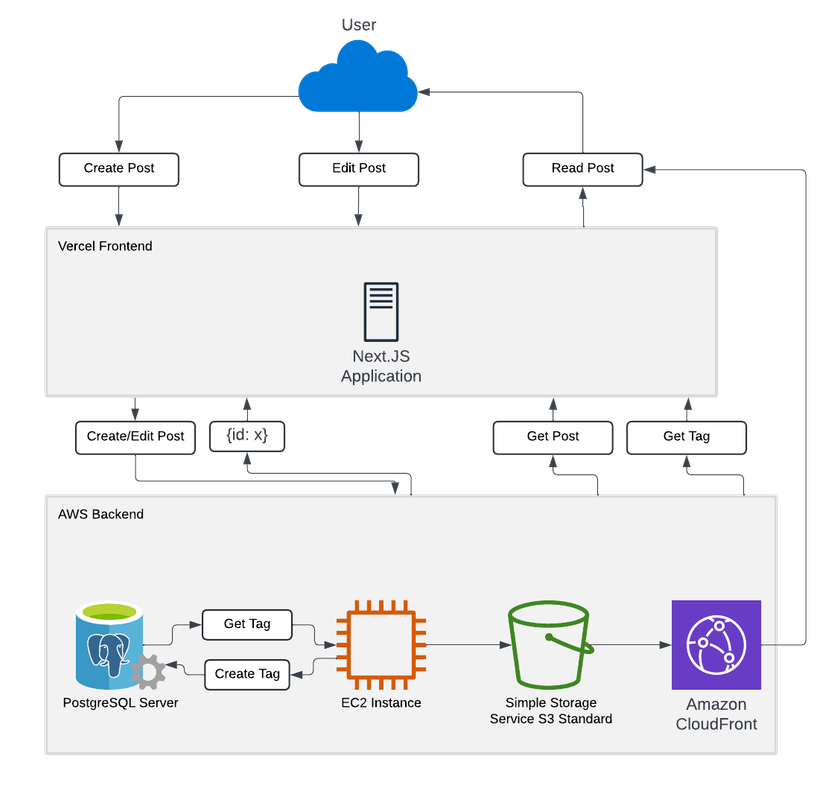
Figure 1
The overview of the architecture for the blog site. As noted, the tag management is left to the back-end currently, but it could be moved up to the front-end with some careful management and API re-arranging. Cloudfront serves as our CDN so read posts that are rendered on the user's end are accessing cached images on the edge.
When I started the implementation of a blog, I figured that not much had to go behind the implementation as the posts themselves were fairly simple and likely to be constructed out of only a few elements; however, once the back-end implementation was sorted out (which will be covered on another post), organizing the front-end was not at all as simple as it was going to be. From the start, I knew that my implementation would require me to fulfill the following:
Create a WYSIWYG editor (or extend a currently available one) to support this blog's common structures.
Create a CSS file that contained all of the styles to be applied to the blog posts extracted from the back-end.
Consider implementing a editor component generic enough to allow post modifications.
Enforce constraints on images that would allow for proper rendering on the page.
Encapsulate all elements within a form tag to allow for server-sided requests to hide API keys / allow checking.
Naturally, point 2) amounted to making sure that when designing the blog editor and blog view page, there would be enough structures shared between both to prevent any odd formatting issues when editing or viewing. Point 4) ended up being implemented as a back-end server-side check since the image reads are performed on the server end, and I wanted to make sure that the passed object to S3 would be consistent with what the Java API had seen. Point 5) was implemented as a front-end server-sided check and fetch using zod. That left points 1) and 3), which went hand-in-hand, and were probably the most difficult parts of implementing the CMS as I was mostly unfamiliar with the front-end side of things.
Extending An Editor
Naturally, I wasn't going to implement everything from scratch when designing a CMS. Sure, you could use a <div> tag with the appropriate contenteditable value set in order to allow for user modifications, but such a design would essentially enforce a two-sided view (similar to that of most LaTeX editors) if anything more complex than raw text was used, and that seemed a bit unnecessary for a simple blog. In the end, after testing a few variants of WYSIWYG editors, I turned to a package called TipTap, which seemed to be consistently used as the editor of choice for multiple blogs that required an extensible editor. TipTap itself is an opinionated and customized implementation of a ProseMirror editor with many plugins implemented for free (and many others available for purchase). The editor's construction itself seemed simple enough. Within the editor, all HTML tags and content were rendered as nodes of a tree, and the design behind component creation reflected that.
The current implementation of the editor uses many predefined components that were already provided by those supporting the development of TipTap, but there was one component that did not have any available extension: the figure tag. One of the most convenient aspects of this tag was the ability to allow for the placement of special text within a figcaption tag which would allow for convenient styling of text that follows an image and provides for a nice logical layout. One of the biggest issues with this implementation, however was that the TipTap base package only allows for placement of a node with only one "hole" (represented by 0), which they basically define as an encapsulated node (or node group):
renderHTML({ HTMLAttributes }) {
return [
'figure', this.options.HTMLAttributes,
['img', mergeAttributes(HTMLAttributes, { draggable: false, contenteditable: false })],
['figcaption', { class: "caption-block" }, 0],
]
},This means that it couldn't be used with the two column image caption style I desired without a bit of wrangling. In order to get around this limitation, the first column is predefined and not able to be set until after the image is created (that way there's only one "hole") and nodes are inserted such that the caption columns are both children of the figcaption tag.
.insertContent({
..., // other args here
content: [
{ // insert our nodes within the "hole"
type: 'paragraph', // column with Figure X
content: [
{
type: 'text',
text: "Figure X"
}
]
},
{
type: 'paragraph', // Column with actual caption
content: [
{
type: 'text',
text: caption,
}
]
}
]
})Because there was a custom command set up for the creation of a figure with a caption as well, I also had to manipulate the input rule factory in order to manually add the two columns to the image caption as, by default, it would use the renderHTML function to define the relevant tags to use, and the single hole limitation applied along with an additional limitation that predefined text within the renderHTML tag would not have the contenteditable attribute properly set even if manually placed.
Finally, in order to keep the structure of the HTML similar to the original post, a section tag component was created and placed into the toolbar. A section is a container for pretty much any other type of node or mark, so it was defined similar to the paragraph component and functions in many of the same ways. With that being finished, all components of the editor toolbar were finished, and the editor implementation was done. However, in order to create a complete blog post editor, there would need to be inputs available for the title of the post, the header image, and the set of tags it contains.
Finalizing the Editor View
The last few parts were fairly straightforward to conceptualize, with the title bar editor simply being an input box with an invisible outline to mimic how the title would normally look in a post. The header image editor was implemented as an image box with a floating bar on the top that would allow for an image upload or image link to be passed and rendered as a preview. The link functionality works perfectly fine, but the upload mechanism wasn't put into place yet largely because I was worried about having unrestricted upload access to the front-end server. I plan on looking into securing an API route and limiting the type of object loaded, but, for now, hosting the image publicly on some other source seems to work just fine.

Figure 2
The current view of the overlay bar for the header image editor. It is presented to the user as an initially hidden, but hover-able, bar that gives the option for either image uploading or image linking in order to set the new header. Error checking is in place and faulty images default back to the original dummy image used for the new post creation defaults.
The tag input was a bit more complex than expected as I wanted a tag input that would shift along with the tags being created on the left-hand side of the input box. To achieve this I simply set up a flex row with a div styled to look like the left side of the input box. The input box then had all default left-side styles removed and set to expand to the width of the parent. In order to properly set up tag inputs, a function was made in order to allow for the addition and removal of tags from a tag reference list, and another function was made in order to handle tag list element deletion events as the typical onChange attribute would not change on a backspace press once the input was completely empty.

Figure 3
The current view of the tag bar in the blog editor. Tags are represented as "badges" and are removable by pressing the backspace key when no text exists in the box. Tags are added upon pressing space in the input box with text that either doesn't have any double quotes, or begins and ends with double quotes. Tags are implicitly created and there is no search functionality in place currently.
Finally, with all elements of the post submission in place, all the post editor needed was a collection of buttons to navigate out of the current page and back to the previous page, and a button to submit the post to the server for creation or update. Placing the buttons was trivial enough, but all of these elements now had to be collected in order to be submitted. Because elements of the form were present in elements that didn't logically follow a form's typical design, I used multiple references to store references to the image component, the input component for the title, and the list of references created by the tag bar. The content of the post itself was attainable by providing a function to modify the current post HTML reference (which was initialized by the user depending on whether a post was being created or updated) with the current content of the editor using the onCreate and onUpdate attributes.
Finally, the editor layout was complete!
Misc. Updates
With that out of the way, there were some other changes to the blog since then, but they are largely minimal for the front-end. Logging in as an admin now provides a user with a way to delete posts and tags when viewing the blog page (they are hidden for normal users as its based off the role assigned from the database). Accessing a blog page as an admin provides the option to modify the given post using the same editor for creation. The normal CSS file used in order to style the post page was slightly modified to be able to be reused for the editor page. The floating image on the back of the front-page was set to be fixed instead of scroll-able in order to address some of the resolution issues that it created. A small bug with the tag viewer container was fixed so it should be able to expand now as more tags are created.
That sums up everything I could think of for the front-end. It probably took me the longest time to properly understand how to design things in a way that made sense and also provided sufficient feedback when connected to the back-end. Thankfully, this experience should make it significantly better when undertaking more complex front-end tasks as Typescript's forced typing has pretty much made looking at the inner workings of unknown components a requirement.
Looking Ahead
There is still a non-insignificant amount of work that needs to be done for the front-end to remain polished and responsive. For starters, assuming the server temporarily goes down, having a statically hosted file containing the default JSON responses would be greatly preferred over displaying an error message to the user and simply preventing any navigation on the site. In fact, the only part of the site that should ever be allowed to be inaccessible should be the blog part of this site, as it's a non-critical aspect of the site and will eventually be fixed on the occasion that it goes down. My goal is to present this blog as a main aspect of the site and hopefully present the information in a way that would be interesting in the front page with the appropriate animations to keep information density high with the smallest screen footprint available.
With that in mind, there still needs to be improvements on the blog creation page. Tags should be searchable, and implicit tag creation should be indicated by the page by using a different outline or color to indicate the potential action. Tags should auto-correct to their original variants if it is improperly capitalized. The image upload mechanism should be made as a temporary hosting that queues the server for potential S3 uploads after which the temporary images can be destroyed. Furthermore, there should be the ability to adjust tag names on-the-fly just as with post names (which would be supported by the back-end as the tag names themselves are not used as the primary keys).
Furthermore, the projects part of the resume page still requires it's default values to be used, and, eventually, explained in-detail in sub-pages dedicated to the projects that made up a large part of my background. An overview of each project will be placed in the resume part of the page (to keep it simple and to the point), but not all projects will get an in-depth exploration as not all of them were large projects that required significant hours of research to perform (or perhaps for non-disclosure reasons).
Until then, I'll continue to write posts regarding the updates made to the site.